
Jason Shaw publishes in Journal of Phonetics
An article by Assistant Professor Jason Shaw and Associate Professor Shigeto Kawahara of Keio University appears in the January 2018 issue of the Journal of Phonetics. The article, entitled The lingual articulation of devoiced /u/ in Tokyo Japanese, investigates the pronunciation of the vowel /u/ in Japanese.
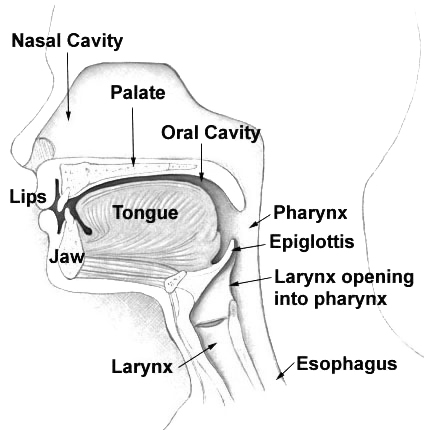
In Japanese, the vowels /u/ and /i/ devoice when they appear between two voiceless consonants. This means that vocal folds do not vibrate when pronouncing these two vowels if they appear between two of the following consonants: /k/, /s/, /sh/, /t/, /ch/, /ts/, /h/, /f/, or /p/. When /i/ is devoiced, its pronunciation sounds as if it were whispered. This can be seen in the word kita “north.” On the other hand, the devoiced /u/ is often silent. For example, the word sutoraiki “strike” sounds like /storaiki/.
Because the /u/ is made silent by devoicing, it is difficult to discern what exactly the mouth is doing when articulating a devoiced /u/. There are possibilities: for instance, the tongue could be moving to the /u/ position in the same way that it would if the /u/ were not devoiced. Alternatively, the tongue could make no attempt to form the /u/ position whatsoever, since the devoiced /u/ will not be pronounced anyway. Yet another possibility is a compromise between the two options: the tongue could still be moving towards the /u/ position, but it could stop short before getting there, forming a reduced gesture.
To answer this question, Jason and Shigeto conducted a study in which the tongue movements of Japanese speakers were recorded using electromagnetic articulography (EMA). In this technique, sensors are attached to various parts of the tongue, as well as the lips and jaw. A special machine is used to track the locations of the sensors over time as the speaker pronounces words in Japanese. This process was repeated for six Japanese speakers from Tokyo, each of whom pronounced ten words: fusoku “shortage,” fuzoku “attachment,” shutaise “subjectivity,” shudaika “theme song,” katsu-toki “when winning,” katsudō “activity,” hakusai “white cabbage,” yakuzai “medicine,” masutā “master,” and Masuda, a common Japanese surname. Five of these words contain a /u/ that is surrounded by voiceless consonants, and is therefore devoiced. The other five are words that sound very similar, except that one of the adjacent consonants is not voiceless, so the /u/ is not devoiced.
The tongue-movement recordings from the EMA study were then analyzed using a computational methodology developed by Jason and Shigeto. First, the recordings are processed by the discrete cosine transformation (DCT) algorithm, which reads each recording and computes four numbers that describe the path along which the tongue travels during each word. Next, a Bayesian classifier compares the DCT numbers for devoiced /u/s and compares them with DCT numbers describing a tongue that moves in a straight line from one consonant to another. If the tongue appears to be moving directly from one consonant to the next, then we can assume that the speaker is not making an effort to pronounce a /u/ vowel. After the analysis, Jason and Shigeto found that speakers sometimes articulate a silent /u/, and sometimes just delete the /u/ altogether. However, they did not find any instances of a reduced gesture: the speakers either fully move the tongue to the /u/ position, or they do not attempt to move it there at all.
The article can be read online at ScienceDirect. A subscription is necessary to access the article.